DinD MTU Size Matters
Foreword
I use Jekyll, a static site generator, to build my blog. And put the workflow of posting new articles under a CI/CD pipeline with Drone CI, integrated with Gitea via webhook. All of these went very well until someday I had my home cluster restarted (yeah, the aforementioned components are all running on my home cluster).
The Crime Scene
The docker build step of Drone CI was failed randomly due to some network timeout issues. The step became tremendously time-consuming. Normally it would take about 3 minutes to complete, but now it takes more than 20 minutes. Even worse, it sometimes ended up with failure. This is totally not tolerable. I got to fix this ASAP.
...
Step 5/11 : RUN bundle install && JEKYLL_ENV=${JEKYLL_ENV} bundle exec jekyll build
---> Running in 7608dc4f4951
Fetching source index from https://rubygems.org/
Retrying fetcher due to error (2/4): Bundler::HTTPError Could not fetch specs from https://rubygems.org/
Resolving dependencies...
Network error while fetching
https://rubygems.org/quick/Marshal.4.8/jekyll-3.9.0.gemspec.rz
(Net::OpenTimeout)
The command '/bin/sh -c bundle install && JEKYLL_ENV=${JEKYLL_ENV} bundle exec jekyll build' returned a non-zero code: 17
time="2021-10-08T06:18:50Z" level=fatal msg="exit status 17"
Here’s the related step in the .drone.yaml:
...
- name: build on push
image: plugins/docker
settings:
registry: registry.internal.zespre.com
repo: registry.internal.zespre.com/starbops/blog
tags:
- latest
- ${DRONE_COMMIT_SHA:0:7}
username:
from_secret: docker_username
password:
from_secret: docker_password
build_args:
- JEKYLL_ENV=development
when:
event:
- push
...
I use the Docker plugin of Drone
CI to build and publish
images to the Docker registry. What this step does is all about project cloning,
image building, and image pushing. For details about image building, here’s the
Dockerfile:
FROM ruby:2.7.1-buster AS build
ARG JEKYLL_ENV=development
COPY blog /app
WORKDIR /app
RUN bundle install \
&& JEKYLL_ENV=${JEKYLL_ENV} bundle exec jekyll build
FROM nginx:1.19.7-alpine AS final
COPY --from=build /app/_site /usr/share/nginx/html
The bundle install line is where the story begins. There must be something
wrong deep down there.
Narrowing Down
As a DevOps engineer (sort of), my intuition is to try out the image building on my local machine since it could be some network issues on the Kubernetes nodes (I forgot to mention that the Drone CI is running on Kubernetes cluster which is in my home cluster). And it turned out everything went smoothly. This proves that the network infrastructure is working as usual, and the source of Ruby gems is also available for downloading.
Second thought: why not run the image building on the suspicious Kubernetes worker node? To get the target node, we need to find out where the Pod was scheduled (for simplicity, let’s assume that the CI workflow is re-triggered):
$ kubectl -n drone get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
drone-59c4ff89fc-pkwmj 1/1 Running 3 63d 10.244.3.159 k8s-worker-3.internal.zespre.com <none> <none>
drone-6e5uk6cu7n7peammeivf 5/7 NotReady 3 36s 10.244.1.113 k8s-worker-1.internal.zespre.com <none> <none>
drone-runner-kube-bc87c4fc4-tkmsz 1/1 Running 3 63d 10.244.2.78 k8s-worker-2.internal.zespre.com <none> <none>
Now we know the Pod was scheduled to worker-1. Do the same image building
process on the worker-1. Unfortunately, the image is built without any
problem. But if we look at it in another angle, we’ve narrowed down the scope
again. It might be the problem inside that specific container, not the worker
node, nor the whole network infrastructure.
We need to get into that container. But maybe we can take a look at the network configuration of the worker node before we dive into the container:
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether d6:af:03:52:f6:56 brd ff:ff:ff:ff:ff:ff
inet 192.168.88.112/24 brd 192.168.88.255 scope global ens18
valid_lft forever preferred_lft forever
inet6 fe80::d4af:3ff:fe52:f656/64 scope link
valid_lft forever preferred_lft forever
<unimportant nics redacted>
5: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:92:85:68:96 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:92ff:fe85:6896/64 scope link
valid_lft forever preferred_lft forever
6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
link/ether 6e:45:4a:da:69:49 brd ff:ff:ff:ff:ff:ff
inet 10.244.1.0/32 brd 10.244.1.0 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::6c45:4aff:feda:6949/64 scope link
valid_lft forever preferred_lft forever
7: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000
link/ether c2:52:5c:f0:4a:59 brd ff:ff:ff:ff:ff:ff
inet 10.244.1.1/24 brd 10.244.1.255 scope global cni0
valid_lft forever preferred_lft forever
inet6 fe80::c052:5cff:fef0:4a59/64 scope link
valid_lft forever preferred_lft forever
<many veth redacted>
59: veth05da7209@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP group default
link/ether d2:0e:75:df:d4:eb brd ff:ff:ff:ff:ff:ff link-netnsid 7
inet6 fe80::d00e:75ff:fedf:d4eb/64 scope link
valid_lft forever preferred_lft forever
Because this is my production environment, there are plenty containers running
on top of this worker node. As you can see, several veth devices are listed,
only one is in our interest, veth05da7209@if3. It is the veth device which
connects to our target container. And all of them are added to the Linux bridge
cni0.
$ sudo brctl show
bridge name bridge id STP enabled interfaces
cni0 8000.c2525cf04a59 no veth05da7209
veth13c268fe
veth14fc7282
veth2ae30c15
veth376dc057
veth514198c0
veth68f59fcb
veth925c56b8
vethf1d952ca
docker0 8000.024292856896 no
Assume we have time machine, we can go back to the time before the Drone CI
pipeline failed. To be more precise, right at the docker build step running.
First, we have to make sure which Pod is our target (Drone CI will create a Pod
for each build triggered. Each Pod might contain multiple containers for steps.
The number of containers generated depends on how many steps you specified in
the .drone.yaml).
$ kubectl -n drone get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
drone-59c4ff89fc-pkwmj 1/1 Running 3 63d 10.244.3.159 k8s-worker-3.internal.zespre.com <none> <none>
drone-6e5uk6cu7n7peammeivf 5/7 NotReady 3 36s 10.244.1.113 k8s-worker-1.internal.zespre.com <none> <none>
drone-runner-kube-bc87c4fc4-tkmsz 1/1 Running 3 63d 10.244.2.78 k8s-worker-2.internal.zespre.com <none> <none>
In our case, the Pod drone-6e5uk6cu7n7peammeivf has 7 containers. It’s
important to find the correct container which executes the step that went wrong
so that we can go into that container to see what just happened. It is the
container with plugins/docker image in this case. You can use kubectl
describe po to check the details.
Let’s dive into that container:
kubectl -n drone exec -it drone-6e5uk6cu7n7peammeivf -c drone-s9oxt5dc00ii5b9wclv9 -- /bin/sh
Take a look at the network configuration via ip address and brctl show:
/drone/src # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if59: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue state UP
link/ether a2:7a:c9:d2:5f:8c brd ff:ff:ff:ff:ff:ff
inet 10.244.1.113/24 brd 10.244.1.255 scope global eth0
valid_lft forever preferred_lft forever
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether 02:42:76:1b:99:61 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
6: veth19bed8a@if5: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue master docker0 state UP
link/ether 9a:16:01:69:38:ba brd ff:ff:ff:ff:ff:ff
/drone/src # brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242761b9961 no veth19bed8a
We can see that the container has one Ethernet interface eth0@if59, one Linux
bridge docker0, and one veth (virtual Ethernet device) pair veth19bed8a@if5.
Also, one end of the veth is plugged into the bridge. It seems that Docker
plugin of Drone CI utilizes Docker in Docker (DinD) to achieve build environment
isolation. We can verify our guess by issuing docker version:
/drone/src # docker version [717/2860]
Client: Docker Engine - Community
Version: 19.03.8
API version: 1.40
Go version: go1.12.17
Git commit: afacb8b7f0
Built: Wed Mar 11 01:22:56 2020
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 19.03.8
API version: 1.40 (minimum version 1.12)
Go version: go1.12.17
Git commit: afacb8b7f0
Built: Wed Mar 11 01:30:32 2020
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: v1.2.13
GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429
runc:
Version: 1.0.0-rc10
GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd
docker-init:
Version: 0.18.0
GitCommit: fec3683
The versions of both client and server are definitely different from the one that runs on the Kubernetes worker node. We’re now pretty sure that there’s a Docker daemon running inside the container. It’s time to find out what’s going on with the container which runs on DinD.
This is where docker build happened:
/drone/src # docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7608dc4f4951 998cf36c9491 "/bin/sh -c 'bundle …" 29 seconds ago Up 24 seconds frosty_dijkstra
/drone/src # docker exec -it frosty_dijkstra /bin/sh
# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
5: eth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
The network configuration of this inner container is relatively simple. It only
has one network interface eth0@if6, which is the other end of the
aforementioned veth pair. And our mission is to execute image building right
here, right now. For convenience, I just execute one of the instructions
specified in the Dockerfile:
# cd /app
# bundle install
Guess what? Same timeout errors occurred! The package downloading progress is intermittent, and with great possibility ends with a failure. Now that we know we’re close to the answer.
Finding the Crux
Since it’s definitely a network-related issue and only occurred in the inner container (DinD), it’s reasonable to look into the network configuration on both containers:
- Outer container, which is running on Kubernetes worker node
- Inner container, which is running on the outer one
Let’s check the relationship between these two containers.
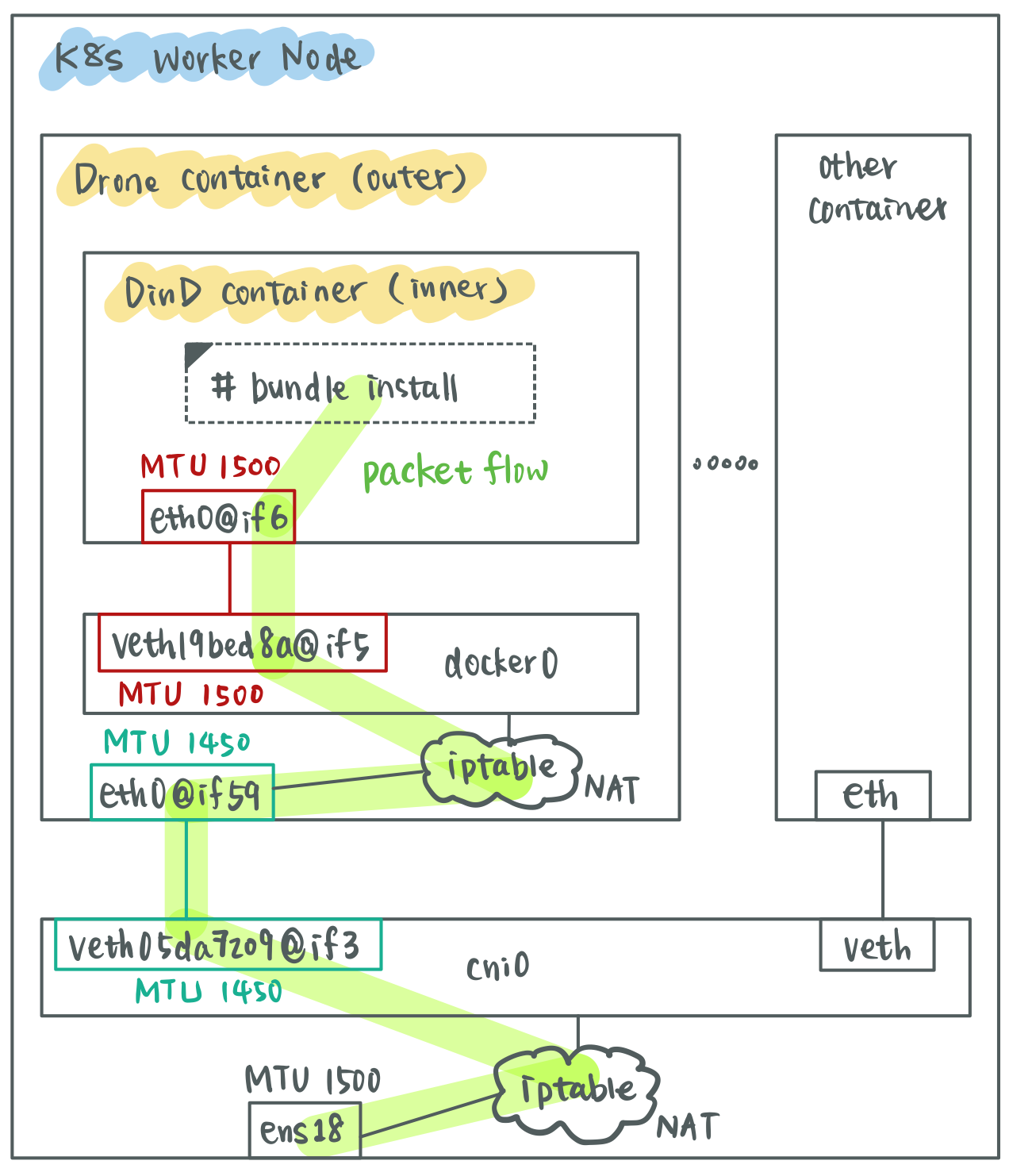
Obviously, there’s something wrong with the MTU size configuration. The MTU size
of veth pair in red (veth19bed8a@if5 and eth0@if6) is configured with 1500
bytes and the other one in green (veth05da7209@if3 and eth0@if59) is
configured with 1450 bytes. The MTU size of the network interface in the inner
container should less than or equal to the one in the outer container. On TCP
connections, which is “downloading Ruby gems” in our case, the initial
connection will be successful: the SYN, SYN/ACK, ACK three-way handshake will
complete since their packet size is rather small. But as soon as the first
packet of greater than 1450 bytes is attempted, the connection may hang if the
MTU mismatch is between two endpoints.
Luckily, the Docker plugin of Drone CI has a parameter called mtu which
configures the MTU setting of the Docker daemon in outer container. Let’s add
the parameter and set it to 1450 in .drone.yaml:
...
- name: build on push
image: plugins/docker
settings:
mtu: 1450
registry: registry.internal.zespre.com
repo: registry.internal.zespre.com/starbops/blog
tags:
- latest
- ${DRONE_COMMIT_SHA:0:7}
username:
from_secret: docker_username
password:
from_secret: docker_password
build_args:
- JEKYLL_ENV=development
when:
event:
- push
...
Trigger CI by committing and pushing the change, then wait for the good news.
Validating Solution
If you’re not comfortable about sitting and waiting for the result, come with me and dive into the container just like what we did in the previous section. Find out the target Pod and container:
$ kubectl -n drone get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
drone-59c4ff89fc-pkwmj 1/1 Running 3 63d 10.244.3.159 k8s-worker-3.internal.zespre.com <none> <none>
drone-i6qj31d5aee65xc8br1r 5/7 NotReady 2 23s 10.244.1.117 k8s-worker-1.internal.zespre.com <none> <none>
drone-runner-kube-bc87c4fc4-tkmsz 1/1 Running 3 63d 10.244.2.78 k8s-worker-2.internal.zespre.com <none> <none>
Go into that specific Drone container:
kubectl -n drone exec -it drone-i6qj31d5aee65xc8br1r -c drone-m9xyzytz8k0piuldgont -- /bin/sh
Check the MTU size of veth pair. Yes, it is configured in 1450 bytes correctly.
/drone/src # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if63: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue state UP
link/ether ae:f6:14:29:a1:ce brd ff:ff:ff:ff:ff:ff
inet 10.244.1.117/24 brd 10.244.1.255 scope global eth0
valid_lft forever preferred_lft forever
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP
link/ether 02:42:a3:0f:07:39 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
6: vethaae3d7e@if5: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue master docker0 state UP
link/ether c6:9b:ab:2e:b9:9d brd ff:ff:ff:ff:ff:ff
/drone/src # brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242a30f0739 no vethaae3d7e
And the inner container’s network interface is in 1450, too.
/drone/src # docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
694c04367e92 7ca21f856a9d "/bin/sh -c 'bundle …" 19 seconds ago Up 12 seconds serene_swartz
/drone/src # docker exec -it serene_swartz /bin/sh
# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
5: eth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
Things are going very well. We should see a big green checkmark coming out for this CI pipeline execution later.
Wrapping Up
Misconfigured MTU size has always been a subtle point when it comes to an unstable system. It’s relatively hard to discover and kind of random, so reproducing it could be difficult. The rule of thumb is to make sure the inner MTU size is smaller than or equal to the outer one. Of course if your system does not add any extra information to the packet header like tunneling, the size of MTU might not be an issue.
References
- Fix Docker in docker network issue in Kubernetes
- docker/dockerd-entrypoint.sh at 92d278e671f32a9ee4a3c0668e46a41f4a3b74b0 · docker-library/docker
- Configure MTU to maximize network performance
- [Day16] CNI - Flannel 封包傳輸原理 - VXLAN分析 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天
- kubernetes之flannel 网络分析
- How to match both sides of a virtual ethernet link?
- What detail symptoms will I be getting if MTU size mismatch?
- IPv4 Fragmentation, MTU, MSS 和 PMTUD